
I love automation. Which engineer doesn’t, huh? When I started doing my first steps in the web (10 years ago, boy time goes by) I copied static files I edited on my computer via FTP to some shared webhost. Even back then I tried to have this deployment process somewhat automated creating bash scripts executing repetitive tasks for me. That was fine for static files, but sucked when I tried the same later with more complex projects, when deployment also included installing dependencies on the host machine and other steps that prepared the runtime environment. Suddenly those script became cluttered with unsafe bash commands, which were also dependent on the underlying OS (-distribution).
The next abstraction layer to make those script at least consistent and easier to manage would be automation software like Ansible1 or puppet2. These are great tools, but still if you want to set up a automated deployment pipeline scripts with those you spend a lot of time just messing with the specialties of your target host’s distribution.
Also there always was that one use case which was incredibly hard to script with both simple bash or shell-automation software: Ad-Hoc deployments of a full stack. Meaning I want my current worktree deployed in a separate environment alongside all its dependencies (usually a database, but often even a lot more like elasticsearch, redis and what not) and possibly seed some test data.
It has always been kind of a bold wish since every single part of my stack could be complex in its requirements or configurations. So yeah, in the pre-containerization world this was unachievable without having enormously complex scripts (with a lot of error prone statements). Then again, it quickly becomes even more complex since sometimes you have to configure resources that are (probably) not on your target host, like DNS, storage or other network infrastructure.
So when Kubernetes became widely adopted I was excited. Declarative configuration of infrastructure, sounds like a dream come true.
If you read the other articles in this blog you might already know that I always try to avoid big cloud providers like GCE or AWS.
- First reason: They are expensive (at least for me tinkering with complex infrastructure, I know that most companies do save money using them).
- Second reason: I don’t like the vendor lock-in happening due to the supremacy of the big tech clouds. I find it alarming if tooling relies on a proprietary vendor instead of platforms.
- Third reason: I still want to understand this software, not have it hidden in an IaaS platform. Deploying it yourself has proven to be good exercise.
Before deploying our Kubernetes cluster I read a lot about this emerging ecosystem. I wish I could provide some super sophisticated reasons why I ultimately stuck with RedHat’s Kubernetes based OpenShift, but the truth is the factors were only the seemingly more extensive documentation and the fact that it provides a web ui by default. After all I didn’t chose a platform for a multimillion dollar project so I just went with it.
Aside from the already mentioned features the obvious difference between a “raw” Kubernetes setup and Openshift would be the creation of endpoints. While Kubernetes lets you create endpoints via an “Ingress rule” configuring the “Ingress Controller” (which is nginx), OpenShift supports “Routes” which basically configure a built-in HAproxy. Also the default security policy is a lot different to the one provided by a “vanilla” Kubernetes rendering a lot of HowTo material unusable for OpenShift users - or at least you have to keep in mind that additional/different steps are possibly necessary, therefore you need to know the differences.
I used the official docs from the OKD (formerly OpenShift Origin) webpage, which is the community edition of RedHat OpenShift, to install our cluster3. The docs were pretty well written in my opinion, but still very complex. How could they not, they cover a lot of things that need to be properly configured before you can abstract them away, like storage, upgrades, load balancing and what not.
Since I wanted a super simple development setup I chose to put “master” and “node” on one machine alongside storage and everything else. Sure that defies most of the reasons to use a platform like this, but as I said - development setup. A possibly interesting note on this: Since distributed storage would be the hardest (and most expensive) part for a simple development setup, I just used this awesome HostPath provisioner . Again, like stated in the README this wouldn’t make ANY sense if you deploy an actual cluster with more than one node. But for a dev setup its just right.
After all this post was not meant to be a tutorial on how to setup up OpenShift but rather explain a use case. That is mainly as a deployment target for our GitLab CI builds. GitLab itself proclaims to have a fully automated CI/CD with Auto DevOps , but only with Kubernetes as a deployment target. Since their “automatic” deployment script relies on some specifics of an original Kubernetes cluster it is not compatible with our OpenShift Cluster 😞. That lead me to dissect the script provided by GitLab, which is you would have to do anyway if your setup exceeded the very limited functionality. Like “my cluster needs a redis”. I actually don’t really get why they provided a rather hacky “Auto DevOps”-Script which supposedly only is applicable to a very few simple use cases. It smells a bit like feature hurry.
Let’s have a look at the GitLab Auto DevOps script . It is a good starting point to give you some inspiration but after all it’s just a bunch of stuff you probably do not want to use. If you want a database they have you covered with postgres, other than that you definitely have to go custom anyway. The interesting part for me was the deployment:
|
|
Huh? So what is helm? A
package manger for Kubernetes
. Its basically packaged yml templates with
declarations for infrastructure. Since infrastructure often looks similar it just makes sense to put declaration of those in a reusable format.
The --set arguments are used for config. Like I already stated this does not work for our OpenShift cluster. You definitely can use helm, but
IN the “chart” (That’s how helm people call their packages) is configuration which relies on the specialties of “vanilla” Kubernetes.
Where does it come from anyway?
|
|
Aha, gitlab provides you with a default helm chart which uses “ingress” for your endpoints, which sadly won’t work in OpenShift. So you need your own chart. The documentation says you can do that by flipping a configuration variable, see docs , but at this point I just chose to roll my own .gitlab-ci.yml, since I couldn’t see the point of meta configuring this rather messy bash script.
I just went with shipping the helm chart right along my project in cases i couldn’t find one in some public repository.
Notice that in case of OpenShift you probably won’t find any, because at least as of now its ecosystem seems to be coupled to “vanilla” Kubernetes.
So most charts only work there.
BUT - it does not take much to convert them, remember the “Ingress” vs “Route” thing. I just replaced the Ingress.yml from the default GitLab Chart:
|
|
And created a very similar “Route” (minus some clutter, I didn’t use):
|
|
So now I have the modified chart in the worktree of my repository and our .gitlab-ci.yml can actually omit downloading the default one. After adding a kubernetes cluster through the GitLab menu, I was ready to go! Finally I am able to have a review environment on any commit, and trigger staging and production deployments with a simple click of a button - more reliable than any script I ever wrote.

Gitlab showing the review pipeline step
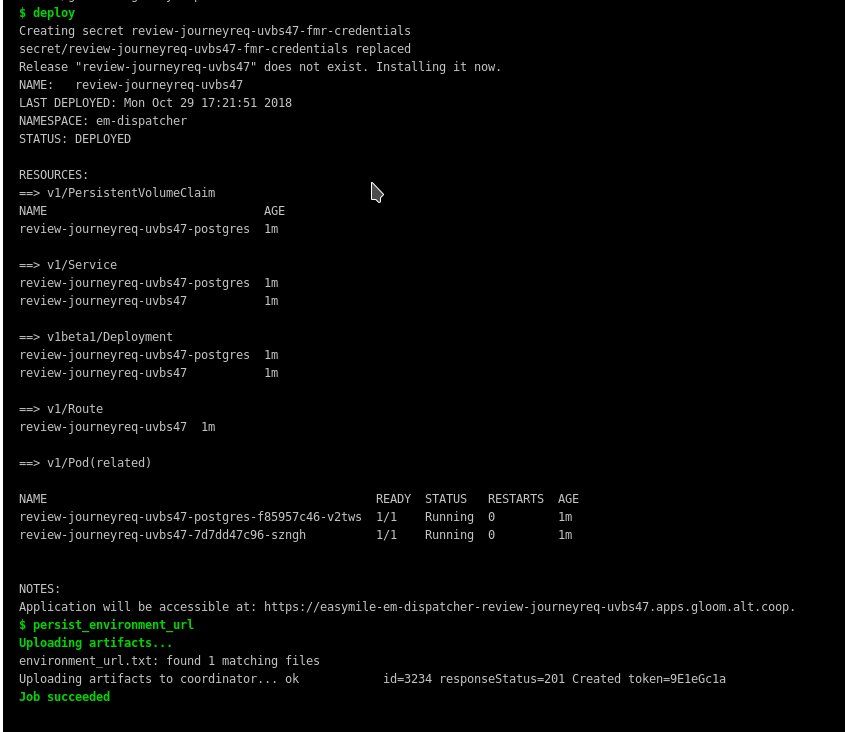
Log output while deploying the review app
After all i don’t have a definitive opinion of whether it is economical to set up Kubernetes for every use-case, for having a cluster reliably available even can be a bit of a pain. What I am certain of, is that the principles coming with it definitely are the future of running server applications. I already find it hard to renounce declarative, versioned, consistent deployments, abstracted infrastructure and automated tasks. It adds a tremendous amount of confidence in your application running in production.